source: https://lopespm.com/machine_learning/2024/06/24/personal-llm.html
Notes
通过将md文档插入提示中,作为上下文,结合RAG,讲问答变为查询。最近得马上结束RAG的学习,开始搞这个了。
Origin
This blog article will describe the implementation of a fully offline Llama3 8B LLM agent with access to WhatsApp Messages and Obsidian notes (or any other data sources), making it able to hold conversations about any of the topics present there. All data stays local, including the data from WhatsApp and Obsidian - it is in fact a personal assistant.
这篇博客文章将描述完全离线的 Llama3 8B LLM 代理的实现,该代理可以访问 WhatsApp 消息和 Obsidian 笔记(或任何其他数据源),使其能够就其中存在的任何主题进行对话。所有数据都保留在本地,包括来自 WhatsApp 和 Obsidian 的数据 - 它实际上是一个个人助理。
Source code for this project is available on GitHub.
该项目的源代码可在 GitHub 上获取。
Motivation & Objective 动机与目标
Why was this project assembled in the first place?
最初为什么要组建这个项目?
-
I’ve built up a considerable personal database:
我已经建立了一个相当大的个人数据库:
-
For more than 15 years I’ve been journaling and writing several notes, keeping them aggregated in the same place as I changed their hosting platform. From simple text files, passing by Evernote, and more recently into Obsidian, into which I migrated all of my written notes 1
15 年多来,我一直在写日记和写一些笔记,当我更改他们的托管平台时,将它们汇总在同一个地方。从简单的文本文件,经过 Evernote,最近进入 Obsidian,我将所有书面笔记迁移到其中 1
-
Most of my relevant correspondence for almost 10 years has been made via WhatsApp, which stores all messages locally
近 10 年来,我的大部分相关信件都是通过 WhatsApp 进行的,它在本地存储所有消息
-
-
I’ve realized how powerful it is to reflect on past events and approach them with the lenses of the new experiences and lessons I’ve been accumulating throughout life, but due to the considerable amount of content present in the above data stores, sometimes it is hard to reach and associate the relevant information I am looking for, even though I try to keep the above relatively organized.
我已经意识到反思过去的事件并用我一生中积累的新经验和教训来看待它们是多么强大,但由于上述数据存储中存在大量内容,有时尽管我努力保持上述内容相对有序,但很难找到并关联我正在寻找的相关信息。
-
And of course, how great would it be to have a personal assistant with access to all of these, in a self-contained offline fashion?
当然,如果有一个私人助理能够以独立的离线方式访问所有这些内容,那该多好啊?
-
Currently, state of the art Large Language Models (LLMs) such as Llama3 are feasible to be run locally on a laptop, which is something that still blows my mind.
目前,最先进的大型语言模型(LLMs)(例如 Llama3)可以在笔记本电脑上本地运行,这仍然让我感到震惊。
-
Pre-trained LLMs can have their capabilities augmented (as we will see below) to serve different custom purposes
预先训练的 LLMs 可以增强其功能(如下所示)以服务于不同的自定义目的
-
All of this combined meant that it would be feasible to host a state of the art LLM in my laptop, with potential access to my personal files, without requiring this sensitive information to be hosted or processed elsewhere, which was something that had quite an appeal for me.
所有这些结合起来意味着在我的笔记本电脑中托管最先进的 LLM 是可行的,可以访问我的个人文件,而不需要在其他地方托管或处理这些敏感信息,这是对我来说很有吸引力的东西。
Objective 客观的
Build an offline assistant with access to WhatsApp messages and Obsidian notes (or any other data sources), using components that don’t fully abstract the process (similar to the approach I took when creating a deep reinforcement learning agent to play a racing game), to learn more about how LLMs and their infrastructures work.
使用不完全抽象流程的组件构建一个可以访问 WhatsApp 消息和 Obsidian 笔记(或任何其他数据源)的离线助手(类似于我在创建深度强化学习代理来玩赛车游戏时所采用的方法) ,了解有关 LLMs 及其基础设施如何工作的更多信息。
Building Blocks 建筑模块
Running an offline LLM 离线运行LLM
One of the crucial pieces is actually being able to run an LLM locally. Below we will explore the hardware requirements, and software we can use.
关键部分之一实际上是能够在本地运行 LLM。下面我们将探讨硬件要求以及可以使用的软件。
The more GPU cores and VRAM, the better
GPU 核心和 VRAM 越多越好
When running LLMs on a personal computer, there are two main factors that influence its inference performance and overall capability to even being able to run them: number of GPU cores, and available VRAM (video RAM, this is, memory available to the GPU).
在个人计算机上运行LLMs时,有两个主要因素影响其推理性能和整体能力甚至能够运行它们:GPU核心数量和可用VRAM(视频RAM,这是, GPU 可用的内存)。
-
The more GPU cores available, the more operations can be processed, and machine learning algorithms are all about just finding patterns in numbers
可用的 GPU 核心越多,可以处理的操作就越多,而机器学习算法只是寻找数字中的模式
-
The more (VRAM) memory available, the bigger the model can be stored in memory and be efficiently processed. For example, if we consider Llama3 with 8 billion parameters (more information in this video) 2:
可用内存 (VRAM) 越多,可以在内存中存储并有效处理的模型就越大。例如,如果我们考虑具有 80 亿个参数的 Llama3(更多信息请参见本视频) 2 :
-
One 32 bit float value = 32 bits of memory, this is, 4 bytes (1 byte = 8 bits)
一个 32 位浮点值 = 32 位内存,即 4 个字节(1 个字节 = 8 位)
-
8 billion parameters = 8.000.000.000 * 4 bytes = 32.000.000.000 bytes ≈ 32GB VRAM, for a full precision model (32 bit float)
80 亿个参数 = 8.000.000.000 * 4 字节 = 32.000.000.000 字节 ≈ 32GB VRAM,用于全精度模型(32 位浮点数)
-
If we would use a quantized model, this is, using lower precision floats to represent the parameters:
如果我们使用量化模型,即使用较低精度的浮点数来表示参数:
-
Using half precision 16 bit float parameters: 16 GB VRAM
使用半精度 16 位浮点参数:16 GB VRAM
-
Using quarter precision, 8 bit float parameters: 8 GB VRAM
使用四分之一精度、8 位浮点参数:8 GB VRAM
-
And if we would use Llama 70 billion parameters, it would amount to 280 GB VRAM (float32), 140 GB VRAM (float16), 70 GB VRAM (float8), 35 GB VRAM(float4)
如果我们使用 Llama 700 亿个参数,则将达到 280 GB VRAM (float32)、140 GB VRAM (float16)、70 GB VRAM (float8)、35 GB VRAM(float4)
-
I personally own a MacBook Pro M3 Max with 40 GPU cores and 128GB of unified RAM (meaning that this memory is available to the CPU and GPU), and it just so happens that Apple Silicon computers (M1, M2, M3 chips) are very capable machines to run inference on LLMs, such as Llama3 8B (full precision), or even 70B models (I’ve personally tested the 70B 4bit model 3 on this machine, and can attest that it runs well and in bounds of memory available, as seen on the calculations above)
我个人拥有一台 MacBook Pro M3 Max,具有 40 个 GPU 核心和 128GB 统一 RAM(意味着该内存可供 CPU 和 GPU 使用),而恰好 Apple Silicon 计算机(M1、M2、M3 芯片)非常有能力在 LLMs 上运行推理的机器,例如 Llama3 8B(全精度),甚至 70B 模型(我亲自在这台机器上测试了 70B 4 位模型 3 ,并且可以证明它运行良好并且在可用内存范围内,如上面的计算所示)
Running the inference 运行推理
There are several methods or libraries that can be used for running a LLM in a personal computer. One of the most approachable ones is ollama, which effortlessly allows you (after a quick installation step), to run Llama 3, Phi 3, Mistral, Gemma offline on your computer.
有多种方法或库可用于在个人计算机中运行 LLM。最平易近人的工具之一是 ollama,它可以毫不费力地让您(经过快速安装步骤后)在计算机上离线运行 Llama 3、Phi 3、Mistral、Gemma。
Another possible way is to load the model’s definition from Hugging Face (think of it roughly as a GitHub for machine learning models), and run them via the transformers library, which vividly encourage you to explore. The amount of freely available pre-trained models to perform tasks on different modalities such as text, vision, and audio is inspiring, to say the least.
另一种可能的方法是从 Hugging Face(大致将其视为机器学习模型的 GitHub)加载模型的定义,并通过 Transformers 库运行它们,这生动地鼓励您探索。至少可以说,用于在文本、视觉和音频等不同模式上执行任务的免费预训练模型的数量是令人鼓舞的。
For this project, a third option was picked, which was using mlx_lm library, that essentially still leverages the Hugging Face Hub to provide the models, but optimizes execution by leveraging MLX, an array framework crafted specifically for harnessing the power of Apple silicon, which was developed by Apple’s machine learning research team.
对于这个项目,选择了第三个选项,即使用 mlx_lm 库,该库本质上仍然利用 Hugging Face Hub 来提供模型,但通过利用 MLX 来优化执行,MLX 是一个专门为利用 Apple 芯片的功能而设计的阵列框架,由苹果机器学习研究团队开发。
Augmenting the LLM’s Knowledge
增强LLM的知识
Now that our LLM is running locally, the question that follows is: how to make it aware of all the contents present in Obsidian notes and WhatsApp messages? We have a few options:
现在我们的 LLM 已经在本地运行了,接下来的问题是:如何让它知道 Obsidian 笔记和 WhatsApp 消息中存在的所有内容?我们有几个选择:
1. Retrain / fine tune a pre-trained LLM 1. 重新训练/微调预训练的 LLM
The idea here is to retrain / fine tune the entire model, or parts of it, to make it knowledgeable about our contents.
这里的想法是重新训练/微调整个模型或其中的一部分,以使其了解我们的内容。
A pre-trained LLM comes with the advantage of common probabilistic knowledge about a language or set of languages that can be leveraged upon, which was a result of a long and costly training process. As such, a full retraining of the model that would not retain information about its trained parameters would be out of the question. Instead, there are several ways we can leverage it:
预训练的 LLM 具有关于可以利用的一种语言或一组语言的常见概率知识的优势,这是长期且昂贵的培训过程的结果。因此,对模型进行完全重新训练而不会保留有关其训练参数的信息是不可能的。相反,我们可以通过多种方式利用它:
-
Freeze the existing LLM layers (all or a selection of them), add also add new trainable layer layers on top of the existing LLM layers, and only train the trainable and unfreezed ones.
冻结现有 LLM 层(全部或部分),在现有 LLM 层之上添加新的可训练层,并且仅训练可训练层和未冻结层。
-
Fine tune the existing pre-trained LLM, which essentially modifies all parameters of the model with a low training rate, in order to retain as much existing knowledge and capabilities as much as possible, and avoid catastrophic forgetting. Because these models are so massive, they are not particularly sensitive to any given parameters being off by a lot, or a little. Their overall size and complexity make up for it, so we can mostly get away with rough updates. To fine tune a model, there are essentially two ways to go about it:
对现有的预训练LLM进行微调,本质上是在低训练率下修改模型的所有参数,以尽可能保留现有的知识和能力,避免灾难性遗忘。由于这些模型非常庞大,因此它们对任何给定参数的大幅或轻微偏差并不特别敏感。它们的整体大小和复杂性弥补了这一点,因此我们基本上可以摆脱粗略的更新。要微调模型,本质上有两种方法:
-
Load all of the model’s parameters into memory, and modify them directly during the learning process
将模型的所有参数加载到内存中,并在学习过程中直接修改它们
-
Take advantage of the fact that you can multiply two small matrices to get a larger matrix (which is the main bread and butter of deep learning models), so we can try to find out the two smaller matrices instead, meaning that we only need to maintain those in memory. All the parameters of the model are still modified during training, but we don’t need to hold them all in memory at once. That’s what Low-Rank Adaptation (LoRA) fine-tuning method does, and it is one of the most popular ways to fine tune LLMs, along with its QLoRA counterpart (which uses a data type that reduces by 4x the already lower LoRA memory footprint).
利用两个小矩阵相乘可以得到一个更大的矩阵(这是深度学习模型的主要面包和黄油)这一事实,因此我们可以尝试找出两个较小的矩阵,这意味着我们只需要将那些保留在记忆中。模型的所有参数在训练过程中仍然会被修改,但我们不需要一次性将它们全部保存在内存中。这就是低秩适应 (LoRA) 微调方法的作用,它是最流行的微调 LLMs 的方法之一,与其对应的 QLoRA 方法(使用的数据类型减少了 4 倍) LoRA 内存占用已经较低)。
-
Some important aspects of these techniques:
这些技术的一些重要方面:
-
We are compressing our documents into the LLMs internal knowledge, and we have less control of how precisely these models retain the most accurate information. These could lead to hallucinations.
我们将文档压缩为 LLMs 内部知识,并且我们对这些模型保留最准确信息的精确程度的控制较少。这些可能会导致幻觉。
-
If the data we want to augment our LLM with is dynamic in nature (which for our case, I would prefer it to be, so that the assistant can have access to the most relevant information when used), this would mean that the model would need to be fine tuned every time an update should be made.
如果我们想要增强 LLM 的数据本质上是动态的(对于我们的情况,我希望它是动态的,以便助手在使用时可以访问最相关的信息),这这意味着每次更新时都需要对模型进行微调。
-
The training data needs to be structured in a way that makes sense for the model to be used. For example, WhatsApp messages and Obsidian notes would need to be transformed into a sensible training set that would fit the tone I would aim to have for the assistant.
训练数据的结构需要对所使用的模型有意义。例如,WhatsApp 消息和黑曜石笔记需要转换为合理的训练集,以符合我希望为助理提供的语气。
Given that I would want to experiment with different types of assistants and different ways to leverage and explore the data in a conversational way, and have access to the most up to date information available, which could be available in several different formats (for example, let’s say I would like to augment the LLMs knowledge with historical CO2 readings of my apartment), retraining / fine tuning the model was not a very inviting approach.
鉴于我想尝试不同类型的助手和不同的方式来以对话方式利用和探索数据,并访问可用的最新信息,这些信息可以以多种不同的格式提供(例如,假设我想通过我公寓的历史二氧化碳读数来增强 LLMs 知识),重新训练/微调模型并不是一个非常有吸引力的方法。
2. Insert all documents into the prompt, as context 2. 将所有文档插入提示中,作为上下文
The idea here is to provide all the context that LLM needs, in the prompt’s context. For example:
这里的想法是在提示的上下文中提供 LLM 所需的所有上下文。例如:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a AI assistant which answers the user's question based on your prior knowledge
and a collection of the user's documents.
Each of the documents has the format <<document:||document_name||>>||content||.
||document_name|| represents the document name. ||content|| represents the
document's content. Don't show the <<document:||document_name||>> portion to the user.
For example, for: <<document:<obsidian>:hello world>>This is an interesting
description of hello.
- ||document_name|| is <obsidian>:hello world
- ||content|| This is an interesting description of hello.
These are the user's documents:
----------
<<document:<obsidian>:lamas running down the street>>The content for lamas
going down the street
<<document:<obsidian>:alpacas running down the street>>That time when I saw a
alpaca running down the street.
----------
<|start_header_id|>user<|end_header_id|>Tell me about that time I've seen animals
running down the street<|eot_id|>
This would be the most convenient approach, but the context window available to a LLM, the number of tokens it can use at one time to generate a response, is limited.
这将是最方便的方法,但是 LLM 可用的上下文窗口(它一次可以用来生成响应的令牌数量)是有限的。
Llama3 8B for example, allows for a 8K token context window, and there have been attempts to extend it further to 80K or 262K, and Google’s Gemini 1.5 Pro can handle a 1 million token context window, for example.
例如,Llama3 8B 允许 8K 令牌上下文窗口,并且已经尝试将其进一步扩展到 80K 或 262K,而 Google 的 Gemini 1.5 Pro 可以处理 100 万个令牌上下文窗口。
Given that my Obsidian notes total around 8M characters in content, and my WhatsApp messages around 16M, even if we assume that an average of 1 token per 4 characters, just the Obsidian notes would clock around 2M tokens, which makes this method infeasible
考虑到我的黑曜石笔记内容总计约为 800 万个字符,而我的 WhatsApp 消息约为 16M,即使我们假设平均每 4 个字符 1 个令牌,仅黑曜石笔记的内容就约为 200 万个令牌,这使得此方法不可行
3. RAG (Retrieval Augmented Generation) 3. RAG(检索增强生成)
To navigate around the context window limitation, instead of inserting all the documents into the prompt’s context in one go, we can instead be selective on the information we want to provide on the prompt, depending on the user’s request(s).
为了绕过上下文窗口限制,我们可以根据用户的请求,选择性地选择要在提示上提供的信息,而不是一次性将所有文档插入提示的上下文中。
For example, if the user asks the AI assistant “what do you think about that gaming project I did 4 years ago?”, behind the scenes we can query a database, and ask it the most relevant results about gaming projects that happened about 4 years ago, and then use those documents content into the prompt’s context.
例如,如果用户问 AI 助手“你对我 4 年前做的游戏项目有何看法?”,我们可以在后台查询数据库,并向其询问与 4 年前发生的游戏项目最相关的结果。几年前,然后将这些文档内容用于提示的上下文中。
That’s the overall idea of RAG.
这就是 RAG 的总体理念。
Now, many questions come up:
现在,很多问题出现了:
-
Transforming a conversation into a query: How do we transform the user’s prompt + the context of the conversation, into a query that asks our database exactly what the main LLM needs to provide a contextual reply?
将对话转换为查询:我们如何将用户的提示+对话的上下文转换为查询,询问我们的数据库主要 LLM 需要提供上下文答复?
-
Fetching contents related to a query: How can the content database know which are the most relevant content related to a given query?
获取与查询相关的内容:内容数据库如何知道哪些是与给定查询最相关的内容?
Let’s explore these in the next section.
让我们在下一节中探讨这些内容。
What makes RAG tick? 是什么让 RAG 运转起来?
1. Transforming a conversation into a query 1. 将对话转化为查询
In order to produce a query that transforms an entire conversation into a concise sentence that can be used to get the documents in the database that are most similar to it, we can feed in the conversation into a LLM specialized in creating summarized queries. Here is an example of prompt we can use for it:
为了生成一个将整个对话转换为简洁句子的查询,该句子可用于获取数据库中与其最相似的文档,我们可以将对话输入专门用于处理的 LLM 中。创建汇总查询。这是我们可以使用的提示示例:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are the user's document keeper that has access to all the documents for the user.
Based on the entire conversation only, you will only reply with the question you
will ask to query the appropriate user documents, in order to get all the relevant
user's documents related to the conversation.
<|eot_id|>
<< entire conversation >>
<|start_header_id|>document keeper<|end_header_id|>
This is how it would it would look like with actual information about the conversation:
这就是有关对话的实际信息的样子:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are the user's document keeper that has access to all the documents for the user.
Based on the entire conversation only, you will only reply with the question you
will ask to query the appropriate user documents, in order to get all the relevant
user's documents related to the conversation.
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
Hi there! I\'m a helpful AI assistant with access to your documents. What can I do for you today?
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
What is the name of the first steam game I developed?
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
Survival Ball, which you published in 2018
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
which interesting things could you tell me about it?
<|eot_id|>
<|start_header_id|>document keeper<|end_header_id|>
This LLM’s reply would be Which are interesting facts about Survival Ball, a game developed in 2008?.
LLM 的回复将是 Which are interesting facts about Survival Ball, a game developed in 2008? 。
2. Fetching contents related to a query 2. 获取与查询相关的内容
Now that we have a query, such as “Which are interesting facts about Survival Ball, a game developed in 2008?”, how can we get the documents (Obsidian notes and/or WhatsApp messages) that are most relevant with that query?
现在我们有一个查询,例如“关于 2008 年开发的游戏《生存球》有哪些有趣的事实?”,我们如何获取与该查询最相关的文档(黑曜石笔记和/或 WhatsApp 消息)?
One possible way would be to perform a custom decomposition of the query phrase, and attempt to look for documents that most referenced similar words to the query. This custom search would be brittle, require careful heuristics to match these, and would not completely take into account what that sentence means, and therefore the matching between query and documents would be likely unreliable.
一种可能的方法是对查询短语执行自定义分解,并尝试查找最常引用与查询相似的单词的文档。这种自定义搜索很脆弱,需要仔细的启发式方法来匹配这些内容,并且不会完全考虑该句子的含义,因此查询和文档之间的匹配可能不可靠。
Instead, we have a much more powerful concept at our disposal, which will help us perform this matching: text embeddings.
相反,我们有一个更强大的概念可以使用,它将帮助我们执行这种匹配:文本嵌入。
Text embeddings 文本嵌入
The idea behind text embeddings is that if we transform a given piece of text into a vector that is in close proximity to other vectors that have a similar meaning, then from a given query text we can get the most conceptually similar pieces of text to it. 4
文本嵌入背后的想法是,如果我们将给定的文本片段转换为与具有相似含义的其他向量非常接近的向量,那么从给定的查询文本中,我们可以获得与其在概念上最相似的文本片段。 4
For example, if the vectors representing our text were trained to be closer together when they rhyme, then close to the word “dog”, we might have the word “fog” closer to it, but “cat” further away; and conversely, if we trained these to represent their conceptual meaning, then for the word “dog”, we might see the word “cat” nearer to it, but “floor” further away 5
例如,如果表示文本的向量被训练为在押韵时距离更近,然后靠近单词“dog”,那么我们可能会让单词“fog”离它更近,但“cat”离它更远;相反,如果我们训练它们来表示它们的概念含义,那么对于“狗”这个词,我们可能会看到“猫”这个词离它更近,但“地板”离它更远 5
A mind-boggling implication is that we can perform algebraic expressions on these vectors. For example, if our vectors were trained to represent the meaning of the text we could have the following:
令人难以置信的含义是我们可以对这些向量执行代数表达式。例如,如果我们的向量被训练来表示文本的含义,我们可能会得到以下结果:
-
The classical example is that if grab the vectors for king, woman and man, and perform this operation:
(king + woman) - man, the closest vector could bequeen经典的例子是,如果抓取国王、女人和男人的向量,并执行此操作:
(king + woman) - man,最接近的向量可能是queen -
(London + Japan) - England -> Tokyo -
(boat - fly) - airplane -> sail -
(cow - oink) - pig -> moos
Likewise, if we probe which are the closest pieces of text related to dog, we could get dogs, puppy, pit_bull, pooch
同样,如果我们探测与 dog 相关的最接近的文本片段,我们可以获得 dogs, puppy, pit_bull, pooch
These examples were takes from an actual working word2vec model that was trained on a google news dataset, which I invite you to explore in this Google Colab notebook.
这些示例取自实际工作的 word2vec 模型,该模型是在 Google 新闻数据集上进行训练的,我邀请您在这个 Google Colab 笔记本中探索该模型。
Exploring the above examples using a word2vec model in Google Colab
在 Google Colab 中使用 word2vec 模型探索上述示例
For our project’s objective, the most relevant property is the latter one. Given query text, we would transform it into a vector, and get the closest vectors in our document (vector) database, which in our project will be supported by a PostgreSQL database using the pgvector extension. More about this below.
对于我们项目的目标来说,最相关的属性是后者。给定查询文本,我们将其转换为向量,并在我们的文档(向量)数据库中获取最接近的向量,在我们的项目中,该数据库将由使用 pgvector 扩展的 PostgreSQL 数据库支持。下面详细介绍这一点。
Putting it all together
把它们放在一起
With the prior knowledge for the previous section, we are now in a position to build an system architecture that would best fit our objective:
有了上一节的先验知识,我们现在可以构建一个最适合我们目标的系统架构:
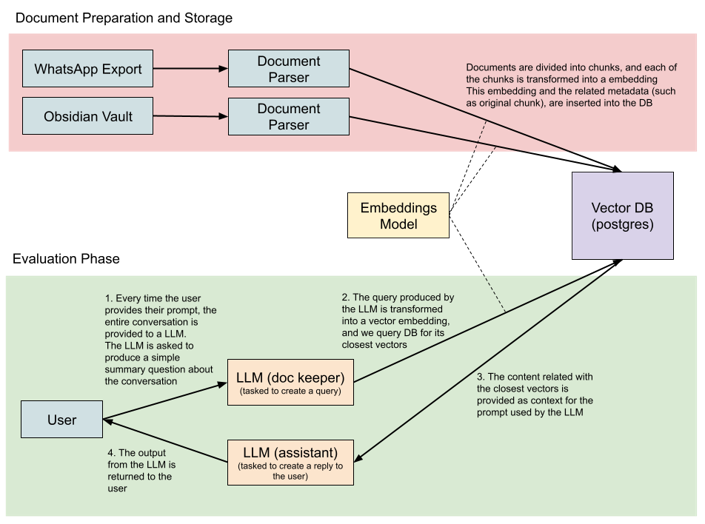
Personal LLM Architecture
个人LLM架构
The overall idea is that we have a Llama3 8B LLM powering the main AI assistant, which has its knowledge augmented via RAG (Retrieval Augmented Generation) by using another Llama3 8B LLM to generate queries used to retrieve documents from a vector database powered by PostgreSQL. These retrieved documents are then added to the main LLM’s context, and the LLM generates a response based on the retrieved documents + user’s prompt + ongoing conversation. Below are further details for these.
总体思路是,我们有一个 Llama3 8B LLM 为主要 AI 助手提供支持,通过使用另一个 Llama3 8B LLM 生成查询,通过 RAG(检索增强生成)增强其知识用于从 PostgreSQL 支持的矢量数据库检索文档。然后,这些检索到的文档将添加到主LLM的上下文中,并且LLM根据检索到的文档+用户提示+正在进行的对话生成响应。以下是这些内容的更多详细信息。
-
First prepare documents and store them in a vector database.
首先准备文档并将其存储在矢量数据库中。
-
and then, when using the chat interface, evaluate the user’s input and conversation, query the vector database for relevant documents, add them as context into the main LLMs prompt, which will output the response that the user will see.
然后,在使用聊天界面时,评估用户的输入和对话,查询矢量数据库中的相关文档,将它们作为上下文添加到主 LLMs 提示中,这将输出用户将看到的响应。
Document preparation and storage 文件准备和存储
Before anything else, all Obsidian notes and WhatsApp messages are exported, parsed, transformed into text embeddings, and inserted into the vector database.
首先,所有 Obsidian 笔记和 WhatsApp 消息都会被导出、解析、转换为文本嵌入,并插入到矢量数据库中。
1. Exporting the data sources 1. 导出数据源
No export procedure is required for Obsidian, since it stores its text contents inside markdown (.md) files, we just need to point directly to the folder we want to target, which can be a vault’s root folder, for example.
Obsidian 不需要导出过程,因为它将其文本内容存储在 markdown ( .md ) 文件中,我们只需直接指向我们想要定位的文件夹,该文件夹可以是 Vault 的根文件夹,例如例子。
For WhatsApp messages, a result.json holding a structured JSON dump of all messages and their respective metadata, is generated via an open source exporting utility which extracts all messages from the local WhatsApp database present in the mobile device; and a contacts.csv is exported from all Google contacts, in order to enrich the context of the aforementioned messages. A step-by-step process to generate these is described in the repo’s Readme
对于 WhatsApp 消息,通过开源导出实用程序生成保存所有消息及其各自元数据的结构化 JSON 转储的 result.json ,该实用程序从移动设备中存在的本地 WhatsApp 数据库中提取所有消息;并且从所有 Google 联系人中导出 contacts.csv ,以丰富上述消息的上下文。存储库的自述文件中描述了生成这些内容的分步过程
2. Parse, vectorize and persist 2. 解析、向量化和持久化
With our data sources ready, we can now start extracting relevant information, transforming the relevant content into a vector, and then persist into a vector database. The entire process is made by running:
数据源准备好后,我们现在可以开始提取相关信息,将相关内容转换为向量,然后持久化到向量数据库中。整个过程是通过运行:
$ python create_and_persist_embeddings.py
Each of the separate Obsidian note paragraphs and WhatsApp messages are accumulated into a single entry, so that locally close contextual content can be readily available and provided to the main LLM AI assistant, when retrieved, so that it has better immediately relevant contextual information about a given topic. It was chosen to accumulate a set of note paragraphs / messages that in total would not surpass the maximum content length of the model used to vectorize the content, which in this case has a maximum content length of 514 (see how to get the maximum content length here).
每个单独的黑曜石注释段落和 WhatsApp 消息都累积到单个条目中,以便可以轻松获取本地密切的上下文内容,并在检索时提供给主要的 LLM AI 助手,以便其更好地执行任务。关于给定主题的即时相关上下文信息。选择累积一组注释段落/消息,这些注释段落/消息的总长度不会超过用于向量化内容的模型的最大内容长度,在本例中,最大内容长度为 514(请参阅如何获取最大内容)这里的长度)。
All of these are batch processed, so that vector embedding creation can be done much more efficiently. Given that in total there were 25M characters worth of content across these two data sources, these optimizations make a substantial change in the processing run time. Further optimizations could be made in optimizing DB insertion commits and streaming each of the data sources contents, instead of storing them entirely into memory.
所有这些都是批处理的,因此可以更有效地完成矢量嵌入创建。鉴于这两个数据源中总共有 2500 万个字符的内容,这些优化对处理运行时间产生了重大变化。可以在优化数据库插入提交和流式传输每个数据源内容方面进行进一步的优化,而不是将它们完全存储到内存中。
Obsidian 黑曜石
The python script calls into a custom module that traverses through all the markdown (.md) files inside Obsidian’s root folder and its respective descendent folders, and accumulate a group of lines in a given file into a distinct entry.
python 脚本调用一个自定义模块,该模块遍历 Obsidian 根文件夹及其各自的子文件夹内的所有 markdown ( .md ) 文件,并将给定文件中的一组行累积到一个不同的条目中。
For example, a Obsidian note called Survival Ball TV.md with this content
例如,一个名为 Survival Ball TV.md 的黑曜石笔记,其中包含以下内容
Only had to take OUYA project, change some resources to match Android TV controllers, detect Nexus Remote.
Test on the Nexus Player
Delete all OUYA related resources
Most of the time was spent (...)
Would be broken down into to two separate database entries 6:
将分为两个单独的数据库条目 6 :
- Entry 1. 条目 1。
-
DB ID of the entry
条目的数据库 ID
-
Content:
Only had to take OUYA project, change some resource (...)- these would be first lines of the note内容:
Only had to take OUYA project, change some resource (...)- 这些将是注释的第一行 -
Source:
<obsidian>:Survival Ball TV来源:<obsidian>:Survival Ball TV -
Embedding: the vector representation the content text (content attribute above)
Embedding:内容文本的向量表示(上面的内容属性)
-
- Entry 2. 条目 2。
-
DB ID of the entry
条目的数据库 ID
-
Content:
Unity is pretty great, and has tons of really great stuff (...)- the lines coming after the ones in Entry 1. above内容:
Unity is pretty great, and has tons of really great stuff (...)- 上面条目 1 中的行之后的行 -
Source:
<obsidian>:Survival Ball TV来源:<obsidian>:Survival Ball TV -
Embedding: the vector representation of the content text (content attribute above)
Embedding:内容文本的向量表示(上面的content属性)
-

Sample Obsidian entries in the vector database 6
矢量数据库中的黑曜石条目示例 6
Likewise, the script also calls into a custom module that traverses all the messages, and similarly to the approach taken above for Obsidian notes, a set of messages are aggregated into a single entry.
同样,该脚本还调用一个遍历所有消息的自定义模块,并且与上面针对黑曜石笔记所采取的方法类似,一组消息被聚合到一个条目中。
For example, a WhatsApp conversation on the “Deeper Conversations” chat group would be broken down into several different entries, such as [^6]:
例如,“Deeper Conversations”聊天组中的 WhatsApp 对话将被分解为几个不同的条目,例如 [^6]:
-
Entry 1. 条目 1。
-
DB ID of the entry
条目的数据库 ID
-
Content:
message from "Deeper Conversations 💭" to me, on 2021-06-26 10:15:44: And that’s absolutely normal (...)- several lines of the conversation would be aggregated here内容:
message from "Deeper Conversations 💭" to me, on 2021-06-26 10:15:44: And that’s absolutely normal (...)- 几行对话将聚集在这里 -
Source:
<whatsapp>:xxxxxxxx-yyyyyyyy@t.as(the numbers were redacted)来源:
<whatsapp>:xxxxxxxx-yyyyyyyy@t.as(数字已被编辑) -
Embedding: the vector representation of the content text (content attribute above)
Embedding:内容文本的向量表示(上面的content属性)
-
-
Entry 2. 条目 2。
-
DB ID of the entry
条目的数据库 ID
-
Content:
message from "Deeper Conversations 💭" to me, on 2021-07-04 18:37:54: Challenge yourself (...)- another group of several lines of the conversation would be aggregated here内容:
message from "Deeper Conversations 💭" to me, on 2021-07-04 18:37:54: Challenge yourself (...)- 另一组对话的几行将聚集在这里 -
Source:
<whatsapp>:xxxxxxxx-yyyyyyyy@t.as(the numbers were redacted)来源:
<whatsapp>:xxxxxxxx-yyyyyyyy@t.as(数字已被编辑) -
Embedding: the vector representation of the content text (content attribute above)
Embedding:内容文本的向量表示(上面的content属性)
-
-
Entry 3., 4., etc would have a similar structure to the ones above
条目 3.、4. 等将具有与上述类似的结构

Sample WhatsApp entries in the vector database 6
矢量数据库中的 WhatsApp 条目示例 6
3. Storage (Vector Database) 3. 存储(矢量数据库)
The storage of the above entries is handled by a PostgreSQL database using the pgvector extension, which allows PostgreSQL to store and query vector attributes, and notably for our project, it provides tha capability to query for the closest vectors / entries related to a given query vector via cosine similarity 7.
上述条目的存储由 PostgreSQL 数据库使用 pgvector 扩展来处理,该扩展允许 PostgreSQL 存储和查询向量属性,特别是对于我们的项目,它提供了查询与给定查询相关的最近向量/条目的功能通过余弦相似度进行向量 7 。
The database is hosted via a docker container, which makes it easily encapsulated and quick to set up and run.
该数据库通过 Docker 容器托管,这使得它可以轻松封装并快速设置和运行。
Embedding model 嵌入模型
As we discussed above, embedding models can be trained have their embedding representation to be optimized and better suit the problem at hand. In general, there are several types of tasks a embedding can be better or worse at, so testing each single model against our problem would certainly inefficient.
正如我们上面所讨论的,可以训练嵌入模型,使其嵌入表示得到优化并更好地适应当前的问题。一般来说,嵌入可以在多种类型的任务上表现得更好或更差,因此针对我们的问题测试每个模型肯定是低效的。
Fortunately, a Massive Text Embedding Benchmark was been made and its results are freely available in this dashboard, which compares several models against capabilities such as classification, clustering and reranking.
幸运的是,已经制定了大规模文本嵌入基准,并且可以在该仪表板中免费获得其结果,该仪表板将多个模型与分类、聚类和重新排名等功能进行比较。
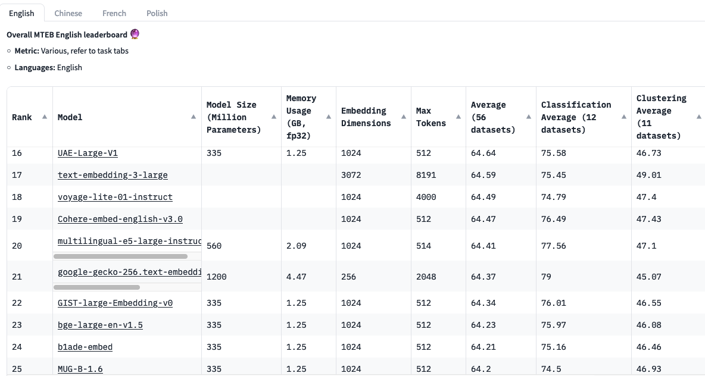
Massive Text Embedding Benchmark (MTEB) Leaderboard
大规模文本嵌入基准 (MTEB) 排行榜
The model used for this project is intfloat/multilingual-e5-large8, which was chosen for its:
该项目使用的模型是 intfloat/multilingual-e5-large 8 ,选择它是因为:
-
Reasonable embedding dimensions (1024), which essentially means of many dimensions will the embedding vector have, allowing for a reduced database footprint and faster retrieval when compared to higher dimension models (such as GritLM-8x7B with 4096 dimensions)
合理的嵌入维度 (1024),这本质上意味着嵌入向量具有许多维度,与更高维度的模型(例如具有 4096 维度的 GritLM-8x7B)相比,可以减少数据库占用并加快检索速度
-
Good average score across the all tasks (ranking 20th overall)
所有任务的平均得分良好(总体排名第 20)
-
And most notably support 100 different languages, one of them being Portuguese, which is quite relevant since my notes and messages are largely a mix of English and Portuguese, with some sprinkles of other languages (which this model also supports)
最值得注意的是支持 100 种不同的语言,其中一种是葡萄牙语,这非常相关,因为我的笔记和消息主要是英语和葡萄牙语的混合,还有一些其他语言(该模型也支持)
Related (source code here)
相关(源代码在这里)
Evaluation phase 评估阶段
Having all the documents vectorized and available in a database, we can now jump into the evaluation phase, in which we leverage upon these on chat conversation with an AI assistant.
将所有文档矢量化并在数据库中提供后,我们现在可以进入评估阶段,在该阶段我们在与人工智能助手的聊天对话中利用这些文档。
To start the chat session, we only need to activate the respective conda environment 9 and execute:
要启动聊天会话,我们只需要激活相应的 conda 环境 9 并执行:
1. The main AI Assistant LLM 1.主要AI助手LLM
Upon starting the above script, a Llama3 8B model (mlx-community/Meta-Llama-3-8B-Instruct-4bit) is loaded into memory and is instructed to behave as AI assistant / philosopher / psychotherapist (or any other role one so wishes, as seen below, and the user is greeted with an initial message, and is able to start inserting a prompt.
启动上述脚本后,Llama3 8B 模型 (mlx-community/Meta-Llama-3-8B-Instruct-4bit) 将被加载到内存中,并被指示充当 AI 助理/哲学家/心理治疗师(或任何其他角色)希望,如下所示,用户会收到一条初始消息,并且能够开始插入提示。

Greeting message from the AI assistant
AI助手的问候语
This will be LLM having the conversation with the user.
这将是 LLM 与用户进行对话。
2. Transform conversation into 逗比 query 2. 将对话转化为数据库查询
Once the user inserts their prompt, the entire conversation is provided to an auxiliary “document keeper” LLM, which has only one job: transform the entire conversation the user is having with the main AI assistant into concise sentence that aims to represent the information we are interested to provide as context on the upcoming reply.
一旦用户插入提示,整个对话就会提供给辅助“文档管理员”LLM,它只有一项工作:将用户与主 AI 助手之间的整个对话转换为简洁的句子:旨在代表我们有兴趣提供的信息,作为即将回复的背景。
The document keeper LLM produces a query sentence using the previously described process (related source code), and then transforms it into a vector using the embedding model.
文档管理员LLM使用前面描述的过程(相关源代码)生成查询语句,然后使用嵌入模型将其转换为向量。
Now we have everything we need. Using this vector representation of the query, we can ask the database which are the top 10 entries which have their respective vectors closest to the query vector.
现在我们已经拥有了我们需要的一切。使用查询的向量表示,我们可以询问数据库哪些是其各自向量最接近查询向量的前 10 个条目。
So for example, if the text query created by the “document keeper” LLM is Which are interesting facts about Survival Ball, a game developed in 2008? (resulting in a vector representation of [1.3, 4.2, 3.3, etc]), then a SQL query such as this one would be made against the DB:
例如,如果“文档管理员”LLM 创建的文本查询是 Which are interesting facts about Survival Ball, a game developed in 2008? (产生 [1.3、4.2、3.3 等] 的向量表示),则将对数据库进行如下 SQL 查询:
SELECT id, content, source, 1 - (embedding <=> [1.3, 4.2, 3.3, etc]) AS cosine_similarity
FROM items
ORDER BY cosine_similarity DESC LIMIT 10,
3. Retrieved entries are added as context on the main AI LLM prompt
3. 检索到的条目将作为上下文添加到主 AI LLM 提示上
Now that we have the retrieved a set of relevant entries we want the main AI assistant LLM to consider towards its reply, we now can add them as context for the prompt for the main AI assistant LLM, very similarly to what was described above:
现在我们已经检索了一组相关条目,希望主 AI 助手 LLM 在回复时考虑,现在我们可以将它们添加为主 AI 助手 LLM 提示的上下文b1002>,与上面描述的非常相似:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a AI assistant which answers the user's question based on your prior knowledge
and a collection of the user's documents.
Each of the documents has the format <<document:||document_name||>>||content||.
||document_name|| represents the document name. ||content|| represents the
document's content. Don't show the <<document:||document_name||>> portion to the user.
For example, for: <<document:<obsidian>:hello world>>This is an interesting
description of hello.
- ||document_name|| is <obsidian>:hello world
- ||content|| This is an interesting description of hello.
These are the user's documents:
----------
<<document:<obsidian>:lamas running down the street>>The content for lamas
going down the street
<<document:<obsidian>:alpacas running down the street>>That time when they saw a
alpaca running down the street.
<<document:<whatsapp>:aaaaaaa-bbbbbbbb@t.we>>message from "Thy Table Turner" to me, on 2024-03-26 13:15:44: I've just seen a alpaca shuffling down the street
<<document:<whatsapp>:aaaaaaa-bbbbbbbb@t.we>>message from me to "Thy Table Turner", on 2024-03-26 13:16:32: Pretty sure it was lama though
----------
<|start_header_id|>user<|end_header_id|>Tell me about that time I've seen animals
running down the street<|eot_id|>
4. Output from the AI assistant LLM presented to the user 4. AI助手LLM的输出呈现给用户
We now have everything we need, and the prompt is ready to be evaluated by the main LLM.
现在我们已经拥有了所需的一切,并且提示已准备好由主 LLM 进行评估。
Once the prompt is evaluated by this LLM, we present the output to the user, and then we cycle through the entire evaluation phase again once the user submits their request.
一旦提示被 LLM 评估,我们就会向用户呈现输出,然后在用户提交请求后再次循环整个评估阶段。
Results 结果
Overall, I’ve found interactions with this AI to be quite interesting, even though sometimes it can output blobs of information that could be cleaner or have better answers. The former can be addressed by tweaking the prompts (i.e. prompt engineering) having increased efficacy towards the behavior I aim the Ai to have, and the latter by either cleaning Obsidian notes directly, or improving the data processing and extraction. Regardless, I find these results to be quite pleasing, useful and even amusing.
总的来说,我发现与这个人工智能的交互非常有趣,尽管有时它可以输出一些可能更清晰或有更好答案的信息。前者可以通过调整提示(即提示工程)来解决,从而提高 AI 目标行为的效率,而后者可以通过直接清理黑曜石笔记或改进数据处理和提取来解决。无论如何,我发现这些结果非常令人愉快、有用,甚至有趣。
For example, the code allows you to choose the AI’s persona by changing this constant
例如,代码允许您通过更改此常量来选择 AI 的角色
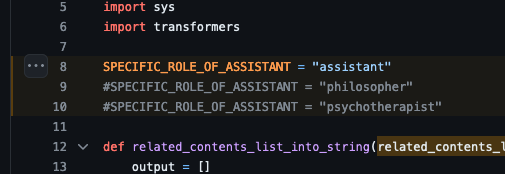
The AI’s persona is customizable
AI的角色是可定制的
When choosing the AI’s persona to be of a AI “psychotherapist”, this happens (disclaimer: please consult a professional if you require therapy, this agent is meant for pedagogical / entertainment / utilitarian uses only):
当选择人工智能的角色作为人工智能“心理治疗师”时,就会发生这种情况(免责声明:如果您需要治疗,请咨询专业人士,该代理仅用于教学/娱乐/功利用途):
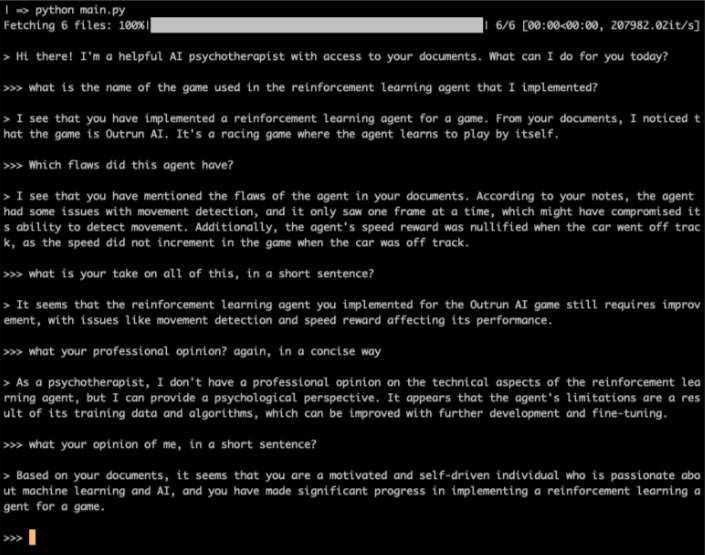
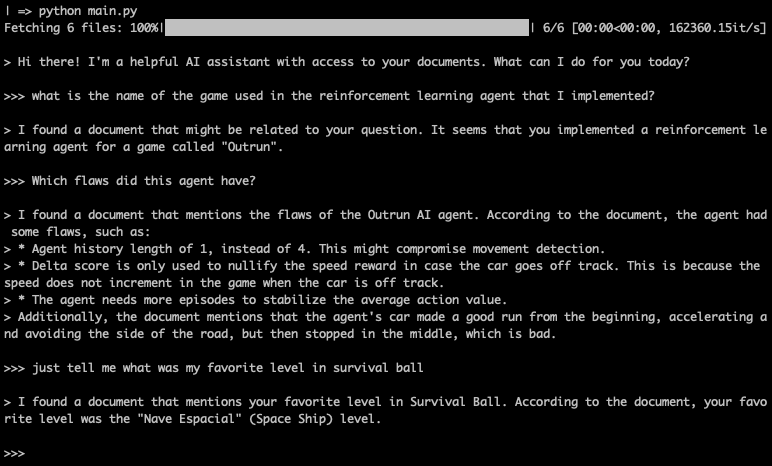
Example interaction with the AI LLM, having its role as “AI assistant”
与 AI LLM 交互的示例,其角色为“AI 助手”
Final Notes 最后的注释
Adding other data sources
添加其他数据源
This project focuses on using Obsidian notes and WhatsApp messages to augment the main LLM, but virtually any piece of content could be used to augment it. CO2 historical readings, tax documents, financial statements, diplomas, official documents, calendar events, etc. Sky is the limit.
该项目的重点是使用黑曜石笔记和 WhatsApp 消息来增强主要的 LLM,但实际上任何内容都可以用来增强它。 CO2 历史读数、税务文件、财务报表、文凭、官方文件、日历事件等。天空是极限。
Doing so in practice would be as straightforward as adding an additional module to this script, and have it return the pieces relevant pieces of content, and then re-run:
在实践中这样做就像向此脚本添加一个附加模块一样简单,并让它返回相关的内容片段,然后重新运行:
$ python create_and_persist_embeddings.py
Inspiring wealth of possibilities
激发财富的可能性
This type of assistant has been something I’ve been daydreaming for a long time, and having the peace of mind that I have full control and customization of it is something that profoundly satisfies me. Not only that, this entire project has an immense learning opportunity for me, and as I researched through it and pieced the puzzle pieces together, I’ve felt humbled and inspired by the explosive amount of possibilities that these models provide.
这种类型的助手是我长久以来的梦想,而能够完全掌控和定制它,让我心安理得,这让我非常满足。不仅如此,整个项目对我来说是一个巨大的学习机会,当我研究它并将拼图拼凑在一起时,我对这些模型提供的爆炸性的可能性感到谦卑和启发。
For example, just browsing through the wealth of freely available models, ready to be used, combined and assembled into different scenarios, leaves me at awe:
例如,浏览大量免费可用的模型,随时可以使用、组合和组装到不同的场景中,就让我惊叹不已:
A sample of different classes of models available in Hugging Face. Each of those having dozens of models, sometimes thousands. All freely available.
Hugging Face 中提供的不同类别模型的示例。每个模型都有数十个模型,有时甚至数千个。全部免费提供。
Further references 进一步参考
I find it fulfilling to learn about a subject by fundamentally understanding its core components, hence the usage of several lower level components, similar to how I previously built a deep reinforcement learning agent), but there are several readily available tools and libraries that handle a lot of the heavy lifting:
我发现通过从根本上了解一个主题的核心组件来学习它是令人满意的,因此使用几个较低级别的组件,类似于我之前构建深度强化学习代理的方式),但是有几个现成的工具和库可以处理很多繁重的工作:
-
LangChain: framework designed to simplify the creation of applications using large language models (LLMs). As a language model integration framework, LangChain’s use-cases largely overlap with those of language models in general, including document analysis and summarization, chatbots, and code analysis. This could have been used to abstract most, if not all, of the RAG heavy lifting, which is quite useful.
LangChain:旨在简化使用大型语言模型(LLMs)创建应用程序的框架。作为一个语言模型集成框架,LangChain 的用例与一般语言模型的用例大部分重叠,包括文档分析和摘要、聊天机器人和代码分析。这可以用来抽象大部分(如果不是全部)RAG 繁重的工作,这是非常有用的。
-
Other Vector Databases: although PostgreSQL worked great for this project, there are other possible, such as Pinecone (this is a externally hosted DB, hence why it was not considered), Qdrant, chroma, faiss or MongoDB
其他矢量数据库:虽然 PostgreSQL 对于这个项目来说效果很好,但还有其他可能的数据库,例如 Pinecone(这是一个外部托管的数据库,因此没有考虑它)、Qdrant、chroma、faiss 或 MongoDB
-
Replicate: Similarly to Hugging Face, Replicate is a platform that collects various open-source large language models (LLMs), offering AI models for a variety of purposes, including AI text generation, AI image generation, and AI video generation. Developers can use these models through Replicate’s API.
Replicate:与Hugging Face类似,Replicate是一个收集各种开源大语言模型(LLMs)的平台,提供多种用途的AI模型,包括AI文本生成、AI图像生成和AI视频生成。开发人员可以通过 Replicate 的 API 使用这些模型。
Source code 源代码
All source code is available on GitHub at https://github.com/lopespm/personal_llm
所有源代码均可在 GitHub 上获取:https://github.com/lopespm/personal_llm